Medallion Architectures Promise Quality Data Products, AI Agents Can Deliver on That Promise
*Aurora has been rebranded Sloan. See Sloan docs here: docs.fiveonefour.com/sloan
- Medallion architectures aim to build trust by delivering on clear quality levels at each stage. This is a good thing, and has been used well by many large organizations, especially those who adopt a data lakehouse architecture.
- However, with capacity constrained data teams and growing demand for high-quality data, the noble intention of this policy is often turned into a process driven checkbox exercise: standards get buried in wikis, SharePoint sites or printed docs—used as proof of policy compliance but not actually guiding the workflow. Standards are relaxed, and backlogs grow.
- Pushing this work to producer and consumer teams (i.e. "data mesh") can relax this bottleneck, but often at the expense of slowing their product delivery speed and reducing the ability to enforce quality standards. Data Engineering Platforms or frameworks can alleviate some of these downsides.
- Agentic AI can unlock the true benefits of medallion architectures, by automating the valuable but too often neglected work that makes medallion architectures really shine: enforcing standards, checking quality, generating docs, etc. — the hard, repetitive work that builds trust.
In our experience, AI agents were able to deliver data to gold standards in a matter of minutes (low single digit hours if you include context gathering) in a level of complexity where such a job ordinarily took days.
Background
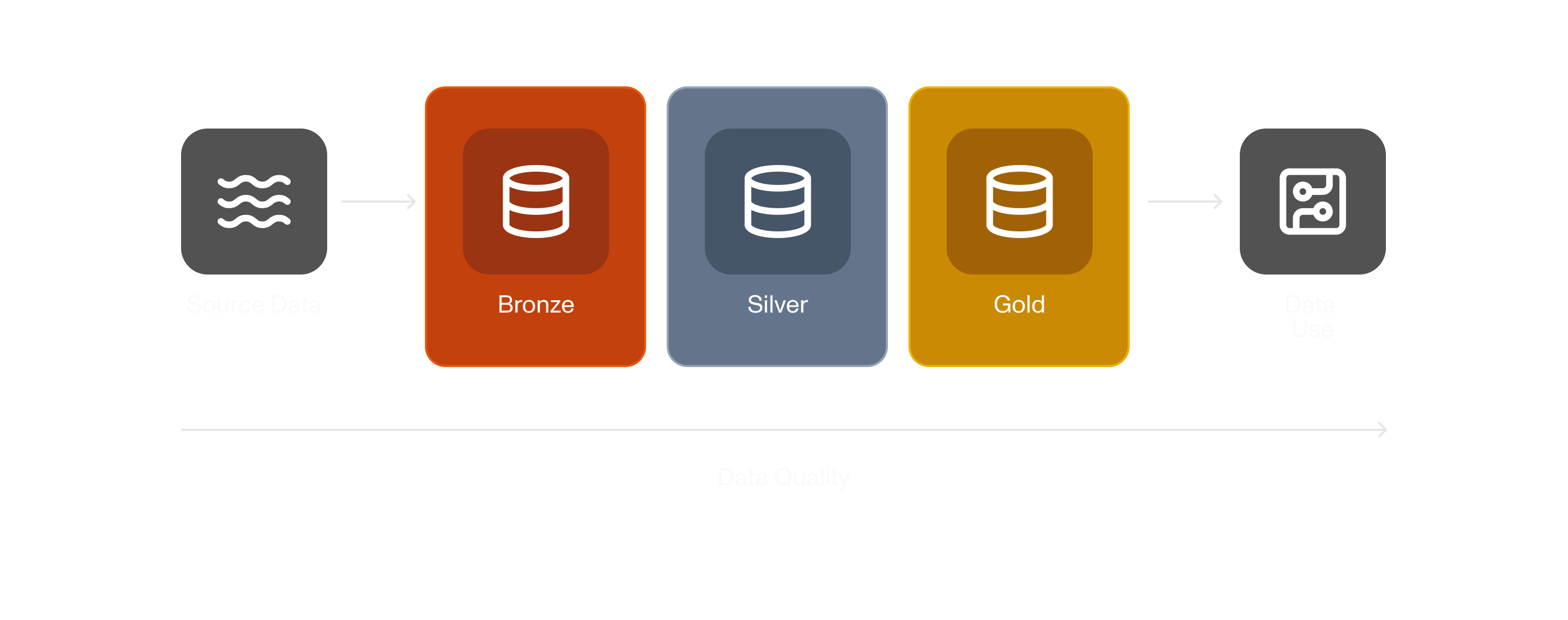
Medallion architecture was widely adopted alongside the adoption of Databrick’s lakehouse architecture, largely to help enterprises with diverse data needs to build scalable data engineering teams. Its primary principals are: data products have different “medallion levels”, and each such level has different quality guarantees.
This allows a team to explore “bronze” unrefined data, or rely on “gold” or “platinum” data products for producing trusted reports. Each level’s standards must be met before that data product is promoted, and the strictness of those standards help build trust in the data product. Ideally, a consumer of the data can consume from the “gold” layer without needing to validate the provenance or quality of the data—a potentially huge increase in velocity on the data consumption side.
On the production side, it also allowed data engineering orgs separate from business orgs to work on promoting those data products by following quality standards set for each level.
Success and trade-offs
The above all looks really great, and that’s why the architecture is so popular amongst data engineering and data platform teams.
As data products get built, promoted and consumed, demand for these high quality data products increase. And demand for the data engineering services of the teams that are administering the architecture tends to increase too. As you can guess, here lies the rub—demand increases but the capacity of the data engineering team doesn’t. This capacity constraint is driven by budget constraints and the sub-linear increase of productivity for labor input in engineering (with overheads in management, coordination, and lack of parallelizeability—two people can’t make 2 minute noodles in a minute).
So for this to succeed the data engineering team needs to become more efficient. This is usually achieved in a couple of ways: (1) implement a systemization of the process (which can lead to being process rather than results or value driven); (2) relax the standards for each layer.
Often it is both: creating standards for compliance and then pushing work through as quickly as demanded, leaving some of those standards behind. And backlogs still grow.
A data engineering lead we spoke to told us that his engineers just didn’t have enough hours in each day to go through all the steps they needed to do to follow and test against the data quality standards that they had signed up for. Our experience tells us that this is common.
Consumers lose trust in the data products they consume, and data engineers have to spend increasing amounts of time fixing the errors caught by the consumers (if they are caught at all).
Solutions: shift work to different developers*
There are two solutions that are possible here. In the first, a data mesh like federated approach pushes the work to upstream data producers, giving them the responsibility to deliver quality data. The second solution leverages advancements in data engineering frameworks and generative AI.
These are individually effective solutions, jointly more effective and one does not require the other.
Federation
Federated data architectures and processes shift data product work away from the central data team–usually the production of the data products falls to producers (i.e. the team that produces the data would be responsible for transforming the data to the bronze or silver layer) and the consumer would build the consumption layer (i.e. producing the gold layer).
The biggest limitation of this approach is the assumption that the data producers and consumers have the data engineering capacity to build. This is the converse of the issue with centralizing—that central data engineering teams lack the subject matter expertise to create meaningful data products.
Accordingly, there comes a pressure for the data engineering team to become more of a data platform team, focusing on empowering the producers and consumers by managing tools and platforms, usually accompanied by building abstractions over the data processing platforms they manage to make it easier for people to build and manage what they mean. Whilst this sometimes reduces the flexibility of the platforms, the ease of use is usually a valid trade-off.
We’re building one of those latest generation developer frameworks: Moose. Data producers can write their data engineering flows needed to create data products in the languages they are using to write their own software (Python, Typescript); this abstracts best in class open source tools (Temporal, Redpanda, Clickhouse, Rust Webservers) etc. to allow these teams without data engineers to build data products scalably.
Data consumers can create their consumption layer similarly—define the egress API or materialized view they want in the language of their choosing and it becomes instantiated in the infrastructure.
AI Agents
As we discussed, why can’t the central data engineering team scale? Increasing demand, steady productivity, increasing quantity of standards, increased minutia and, really, endlessly detail oriented data cleaning / validating / deduplicating / …
We said both solutions add data engineering capacity, but that capacity can be an AI agent. In fact, AI agents are particularly good at this kind of work.
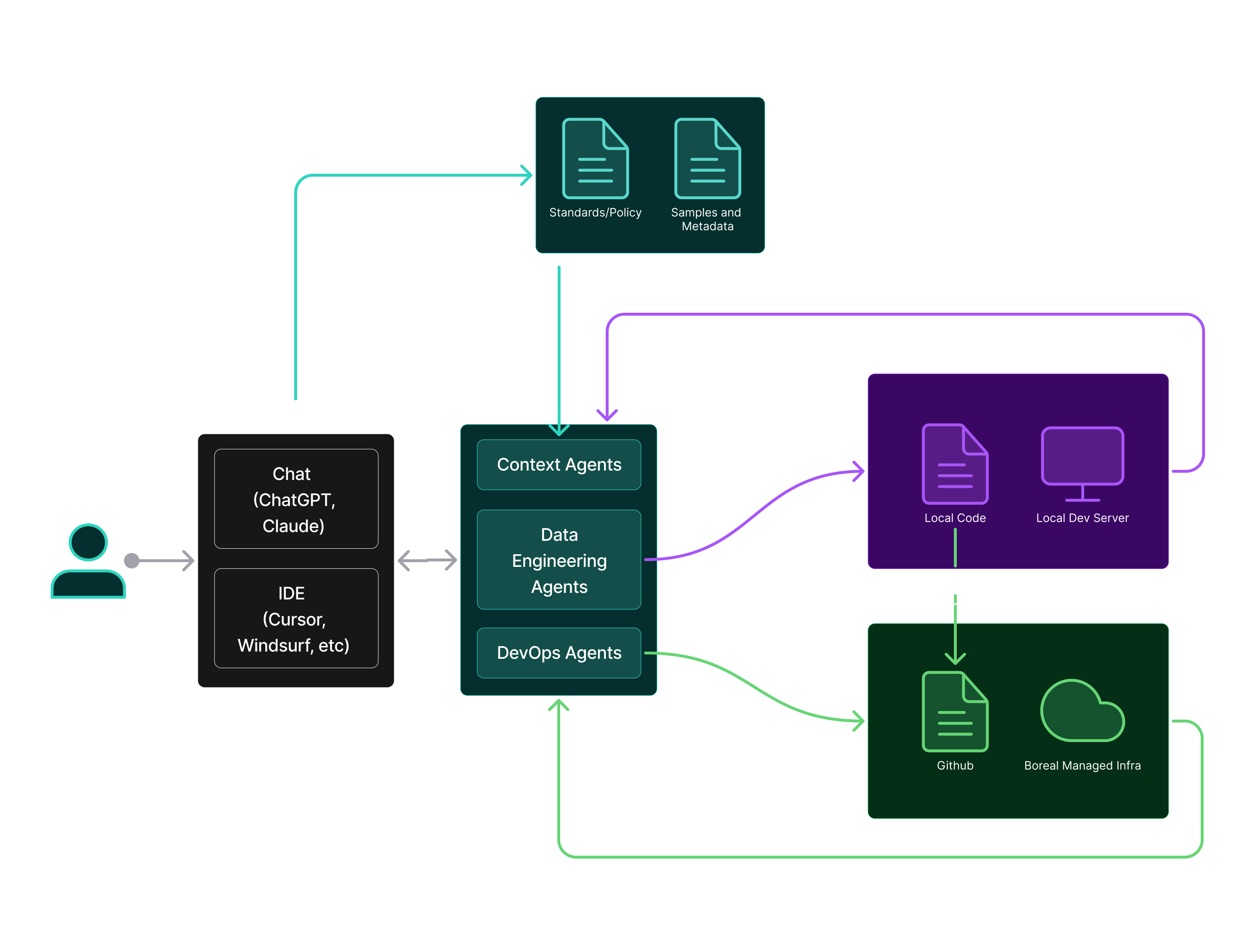
Agents are defined by their loops: they have a goal (i.e. pass some test), they have context, and they can use tools to solve for that goal. The tools usually do a thing with some side effects (e.g. create a data pipeline, side effects being data in a database, logs in a dev server, etc.) that add additional context for the agent. The agent acts and tests until they solve the problem or run out of attempts.
Our current best approach to this is as follows:
- Set up context: ingest the wikis and sharepoint documents and policies that define the quality standards, create actionable, testable quantitative and qualitative tests to be used by the agents in defining the quality of the data
- Ingest the subject data and its context: provide access to the raw data and any associated metadata that can help the agents improve the quality of the data
- Start the agent loops going to improve the data quality from bronze to silver to gold layers
The agent loop here is simple:
- Take the result of the test
- Create a “promotion plan” for improving the data to the next quality level
- Create a data pipeline to clean / improve the data
- Test the data again
- 🔁
The agents don’t care about the tedium of the data cleaning work, they can work in parallel, and they can do the repeated data quality improvement work tirelessly and effectively.
A data architect we spoke with recently said: “the agents are doing data engineering the way our data engineers would do if they had more time”.
They deliver a data product at quality, and, unlike human actors, without any extra work they generate a literal checklist showing that all the data quality standards are met (or, if they aren’t, which aren’t and why).
Agents that aren’t limited to an IDE can also gather further context (e.g. via slack, teams, email, jira, etc.) from data producing or consuming teams, helping to draw together the information needed to make a specification for a gold level data product.
One of the hard things about developing with AI agents is ensuring that they can “one shot” the solution, or, if not, that they are able to draw in enough additional context to keep moving towards a real (non-hallucinated) solution to the problem.
At Fiveonefour, we’ve approached this problem with three main pillars (creating our Aurora product):
-
Our developer framework Moose drastically reduces the “surface area” the agent has to deal with. By way of example, a single Moose data model file allows the agent to instantiate one or more of an ingest API, data stream, OLAP table.
-
Our developer environments (local or cloud) feed AI comprehensible telemetry and errors back to the agent, as well as giving them recourse to the infrastructure (reading the data models and schemas, streams, tables, etc.) to see the result of their actions.
-
Our tools help the agents plan, manage context and evolve their prompts to move towards a solution.
Conclusion
Medallion architectures are an enterprise-scale solution to building high quality data products that surprisingly has growing pains with scale. Most of these problems are derived from the architecture’s success: better products mean more demand; with static capacity either lead times are completely blown out or quality drops.
There are solutions to this problem that preserve the premise of medallion architecture:
- Federating data engineering work away from central data engineering
- Using central data engineering to support those teams by building scalable abstractions to data product creation
- Supplementing data engineering capacity with AI agents
Agents are already sufficiently high quality to do this work; it is easier than you think to get started
With MCPs and the latest generation of agents (really, since Claude 3.5), agents are writing good enough code to do this work (see example below).
To get started, it can be as simple as using an agent-enabled IDE (like Cursor or Windsurf) against your existing data engineering code and quality standards documentation. MCPs like Clickhouse’s, Fiveonefour’s Aurora MCP, DuckDB’s MCP and many others can arm your agents with the tools they need to deliver high quality data products at scale.

An early prototype where the agents created data models representing the bronze data product redacted_data_bronze, compared that against the condensed data standards data_standards.md, generated a proposed silver data model redacted_data_silver.ts and set of transformations based on the data product promotion plan RedactedDataPipeline_quality.md .
Interested in learning more?
Sign up for our newsletter — we only send one when we have something actually worth saying.
Related posts
All Blog Posts
OLAP, AI, ClickHouse
Data modeling for OLAP with AI ft. Michael Klein, Director of Technology at District Cannabis
District Cannabis rebuilt its entire data warehouse in just four hours using AI-assisted OLAP modeling. See how Moose copilots optimized raw Snowflake data for ClickHouse performance—with tight types, smart sort keys, and clean materialized views.

ClickHouse, Data Architecture, Developer tools
Evolving the ORM for the Analytical Database
Traditional ORMs break when applied to OLAP databases. We worked with ClickHouse to explore why columnar stores require a new, OLAP-native approach to developer abstractions