Blog
Stay up to date with the latest news, updates, and insights from our team.

Product
Analytical dashboards and AI chat: from parquet in S3 to deployed production app
A step-by-step guide showing how to bootstraps a MooseStack MCP project with Parquet data from S3, generate ingest pipelines, load ClickHouse, test with chat, build a Next.js frontend, and deploy securely to Boreal and Vercel.

OLAP
OLAP migration complexity is the cost of fast reads
In transactional systems, migrations are logical and predictable. In analytical systems, every schema change is a physical event—rewrites, recomputations, and dependency cascades. This post explains why OLAP migrations are inherently complex, the architectural trade-offs behind them, and how to manage that complexity.

OLAP, Product
Ship your data with Moose APIs
You’ve modeled your OLAP data and set up CDC—now it’s time to ship it. Moose makes it effortless to expose your ClickHouse models through typed, validated APIs. Whether you use Moose’s built-in Api class or integrate with Express or FastAPI, you’ll get OpenAPI specs, auth, and runtime validation out of the box.

OLAP
How a Nix flake made our polyglot stack (and new dev onboarding) fast and sane
Our data platform spans Rust, TypeScript, and Python—and used to take 30+ minutes to set up. With Nix Flakes, onboarding dropped to five minutes. Here’s how we built a reproducible, composable dev environment for our entire polyglot stack.

OLAP
10 Key Takeaways About OLAP — For Telecommunications Operations Leaders
OLAP turns telecom data—from CDRs to telemetry—into instant insight for NOC, field, and care teams. Learn 10 key lessons on how modern OLAP architecture drives real-time visibility, AI-ready analytics, and faster operational decisions across telecom networks.

OLAP, AI, ClickHouse
Data modeling for OLAP with AI ft. Michael Klein, Director of Technology at District Cannabis
District Cannabis rebuilt its entire data warehouse in just four hours using AI-assisted OLAP modeling. See how Moose copilots optimized raw Snowflake data for ClickHouse performance—with tight types, smart sort keys, and clean materialized views.

OLAP, Product, Python
Just OLAP It (Python Edition): Derive Moose OLAP Models from SQLModel
This hands-on walkthrough shows how to derive Moose OLAP models directly from Python’s SQLModel. You’ll learn how to map your OLTP schema to ClickHouse through MooseStack — defining OLTP models, mirroring them into Pydantic payloads, layering in CDC metadata, and declaring OLAP tables. While TypeScript automates much of this flow, Python requires explicit type bridging. This post highlights what’s manual today, where automation could fit, and how to keep your OLTP and OLAP layers in sync.

OLAP, OLTP, ORM
Just OLAP it: derive an OLAP data model from your OLTP ORM
Most developers love their ORMs — but what happens when you move from transactional (OLTP) to analytical (OLAP) workloads? This post explains how to reuse your existing TypeScript ORM types (from Drizzle, Prisma, or TypeORM) to build OLAP-ready schemas in ClickHouse using MooseOLAP. You’ll learn how to make implicit OLTP assumptions explicit, add OLAP-specific semantics like strict types and partitioning, and keep type safety while achieving true analytics performance.

OLAP, OLTP, ClickHouse, Redpanda
Code first CDC from Postgres to ClickHouse with Debezium, Redpanda, and MooseStack
Learn how to keep OLTP fast while streaming changes to ClickHouse for lightning-quick analytics. This code-first guide uses Debezium, Redpanda, and MooseStack to model CDC, transforms, and OLAP tables you can spin up locally in seconds.

OLAP, ClickHouse
ClickHouse table engines and CDC
OLAP databases don’t update — they merge. When streaming CDC data into ClickHouse, every change is an insert. The table engine you choose defines how those inserts turn into a correct, queryable view of your data.

OLAP, ClickHouse, Product
Optimizing writes to OLAP using buffers
Learn how insert patterns differ between OLTP and OLAP databases — and how ClickHouse and MooseStack can help you optimize for each. From batching strategies to streaming buffers, discover practical heuristics to balance performance, freshness, and resilience.

OLAP, ClickHouse
OLAP on Tap: Freddy v JSON (the new JSON type)
ClickHouse’s new JSON column type bridges the gap between flexibility and OLAP efficiency. This post explores how explicit and implicit subcolumns let you query nested data without sacrificing performance — and why understanding how ClickHouse handles NULLs is key to modeling real-world JSON.

OLAP
10 Key Takeaways About OLAP — For Sports & Entertainment Finance Leaders
OLAP is the engine behind real-time financial analytics in sports and entertainment. From live event P&Ls to AI-driven forecasting, here are 10 lessons for finance leaders modernizing their data stack and decision-making.

OLAP, ClickHouse
OLAP on Tap: Much Ado About Nulling
When working with OLTP databases, NULL values are a flexible way to represent unknown data. But in the world of OLAP — where performance depends on columnar efficiency and compression — NULL can become an expensive mistake. In this post, we unpack why NULLs slow down analytical workloads, how ClickHouse handles them internally, and what patterns (like sensible defaults or sentinel values) you can use instead.

OLAP, ClickHouse
OLAP On Tap: Untangle your bird's nest(edness) (or, modeling messy data for OLAP)
Nested and irregular data structures are powerful for ingestion—but brutal for analytics. This article explores why JSON-heavy and shape-shifting data patterns complicate OLAP performance, and how to tame them with schema-on-write strategies, materialized views, and ClickHouse tricks. Whether you’re modeling logs, telemetry, or e-commerce data, you’ll learn how to keep the elegance of nested data without losing analytical speed.

OLAP, ClickHouse
OLAP on Tap: The Art of Letting Go (of Normalization)
This article explains how OLAP databases like ClickHouse and DuckDB differ fundamentally from OLTP systems in their design and purpose. It dives into how columnar storage and analytical workloads reshape schema design, comparing traditional star schemas with modern wide, denormalized tables. You’ll learn why storage duplication is no longer the enemy, why joins slow down analytics, and how schema design in OLAP effectively is the query plan.

OLAP, ClickHouse
OLAP on Tap: ORDER BY defines your performance
This post explores why ORDER BY is a critical performance factor in OLAP databases like ClickHouse. Using clear analogies (like grocery store layouts vs. maps) and real-world benchmarks (aircraft telemetry data from ADSB.LOL), it shows how ORDER BY improves efficiency compared to OLTP indices. You’ll also learn practical heuristics for choosing the right fields — from low-cardinality booleans to time-based clustering — and how they impact ingestion, compression, and query speed.

OLAP, ClickHouse
OLAP on Tap: High time for low cardinality
Cardinality plays a critical role in OLAP database performance, especially when balancing compression, encoding, and query efficiency. This guide breaks down cardinality types with practical examples, including LowCardinality wrappers, enums, and heuristics for choosing the right column types. Perfect for engineers optimizing high-volume analytics workloads.

ClickHouse, OLAP
OLAP on Tap: You're just my type
The article talks about why typing matters in OLAP systems like ClickHouse, covering efficient type choices, when to use LowCardinality, and the tradeoffs of strict schema design, with a guide for AI copilots and links to best practices.

OLAP
10 Key Takeaways About OLAP — For Modern CFOs and Finance Leaders

User-facing analytics, Product, Developer tools
Reference apps by Fiveonefour: The learning behind creating Area Code
At Fiveonefour, we built Area Code—a reference application that demonstrates how to add an analytical layer to a transactional system using our OSS framework, MooseStack. This blog introduces why we created Area Code, the challenges it addresses, and the insights we’ve gained from building it. It’s the first in a series of articles sharing our learnings with the community.

ClickHouse, Product, Educational, Community
You Showed Up: What We Learned from Asking “Does OLAP Need an ORM?”
We asked the community if OLAP needs ORM-like DX. The consensus: keep SQL first-class, add type-safety and contracts, and build toward a semantic layer. Here are the sharpest arguments—and what we’re building next.

ClickHouse, Data Architecture, Developer tools
Evolving the ORM for the Analytical Database
Traditional ORMs break when applied to OLAP databases. We worked with ClickHouse to explore why columnar stores require a new, OLAP-native approach to developer abstractions

Product, Educational, Software Architecture
Prototyping a Connector Factory: Build first to learn, abstract later to scale
The Connector Factory reimagines data integrations by combining clear specifications, standardized scaffolding, and AI-powered agents to deliver production-ready connectors in hours instead of weeks. By turning every new connector into a learning loop, the system continuously improves—making integrations faster, more reliable, and fully open source for developers to use or extend.

ClickHouse, Educational
PostgreSQL vs ClickHouse: What I Learned From My First Database Benchmark
Joj benchmarked PostgreSQL vs ClickHouse on 10M rows to see how an AI agent might explore data. The test revealed when ClickHouse pulls ahead, how one schema change delivered a 50× speedup, and why LLMs make these optimizations easier than ever.

Update, New feature
Introducing Lifecycle Management: Taking Control of Your Database Evolution
Lifecycle Management gives you fine‑grained control over how Moose applies schema changes as your code evolves—keep automation in dev, add deletion‑safe guardrails in prod, or integrate with CDC/external databases for full control. Choose per resource—Fully Managed, Deletion Protected, or Externally Managed—across tables, streams, and ingestion pipelines. Available now in v0.4.320+; docs: moose.514.dev/moose/building/lifecycle.

Product, Update
Fixing Ctrl+C in Rust Terminal Apps: Child Process Management
Lessons we learned from Moose CLI to keep terminals clean after Ctrl+C—no more garbled prompts or lingering processes.

ClickHouse, Educational, AI
ClickHouse x Fiveonefour
ClickHouse is a blazingly fast open source analytical database. We love Clickhouse here at Fiveonefour, and we’re on a mission to make Clickhouse accessible to every developer. If you’re a developer building on ClickHouse, you’ve come to the right place ;) Read on to learn about Fiveonefour's dev tool stack to enable Clickhouse developers...

Product
Getting DDL Dependencies in order with Moose & SQL
If you've worked with SQL databases like ClickHouse, you know that changing one object—say, a table—can have ripple effects on dependent objects like Materialized Views (MVs) or other views. Applying these Data Definition Language (DDL) changes in the wrong order often leads to errors and headaches. This post explains how Moose handles these SQL dependencies to make your infrastructure updates reliable during development with moose dev.

Next.js, Educational, Templates
Real-time Github Analytics with ClickHouse, Redpanda
Build a real-time GitHub analytics dashboard in a few hundred lines with Moose. Learn to ingest and enrich GitHub data, expose a type-safe API, and deploy a production-ready stack—all with minimal code and maximum speed. Perfect for tracking open-source trends or launching your own analytics project.

AI, Data Architecture
Medallion Architectures Promise Quality Data Products, AI Agents Can Deliver on That Promise
Medallion architectures aim to deliver high-quality data products through distinct quality levels but face scalability issues as demand for these products increases. AI agents can address this by automating data quality improvement, speeding up the process from bronze to gold levels while maintaining high standards. Combined with federated data architectures and scalable frameworks, AI agents can significantly enhance data engineering capacity and deliver high-quality data at scale.

AI
The MCP Economy
The blog explores how Model Context Protocols (MCPs) are emerging as the next evolution beyond traditional APIs, enabling LLMs to interact with systems in flexible, agent-native ways. Just as APIs turned complex backend tasks into simple programmatic calls for apps, MCPs abstract complexity for LLMs, but require handling non-determinism and reasoning, not just static tasks. This shift could create a new wave of "API winners" in domains previously considered too human-centric to automate.

Templates, Product, AI
Goodreads Book Review Dataset Template
The blog post discusses how the author created a template to ingest Goodreads data from Kaggle to demonstrate the capabilities of their advanced AI tools, including data ingestion and analysis. It provides a detailed guide on how to set up the tools, ingest the dataset, explore the data with AI, and even productionize results .

Educational, Data Products, AI, Templates
Aircraft Transponder (ADS-B) Data Template and Aurora MCP Analytics Engineer
This blog walks through setting up a Moose project to track military aircraft data using a Moose / Aurora ADS-B template, with a focus on leveraging Aurora MCP tools for data exploration and productionizing APIs. It provides a step-by-step guide to exploring and analyzing transponder data, using Claude Desktop and Cursor for insightful queries and visualizations.

Product, AI
MCP Configuration Management by CLI
The blog post discusses the challenges of using MCPs in different clients, particularly Claude Desktop and Cursor, with frustrations around config JSON setup, updates, and PATH inheritance.
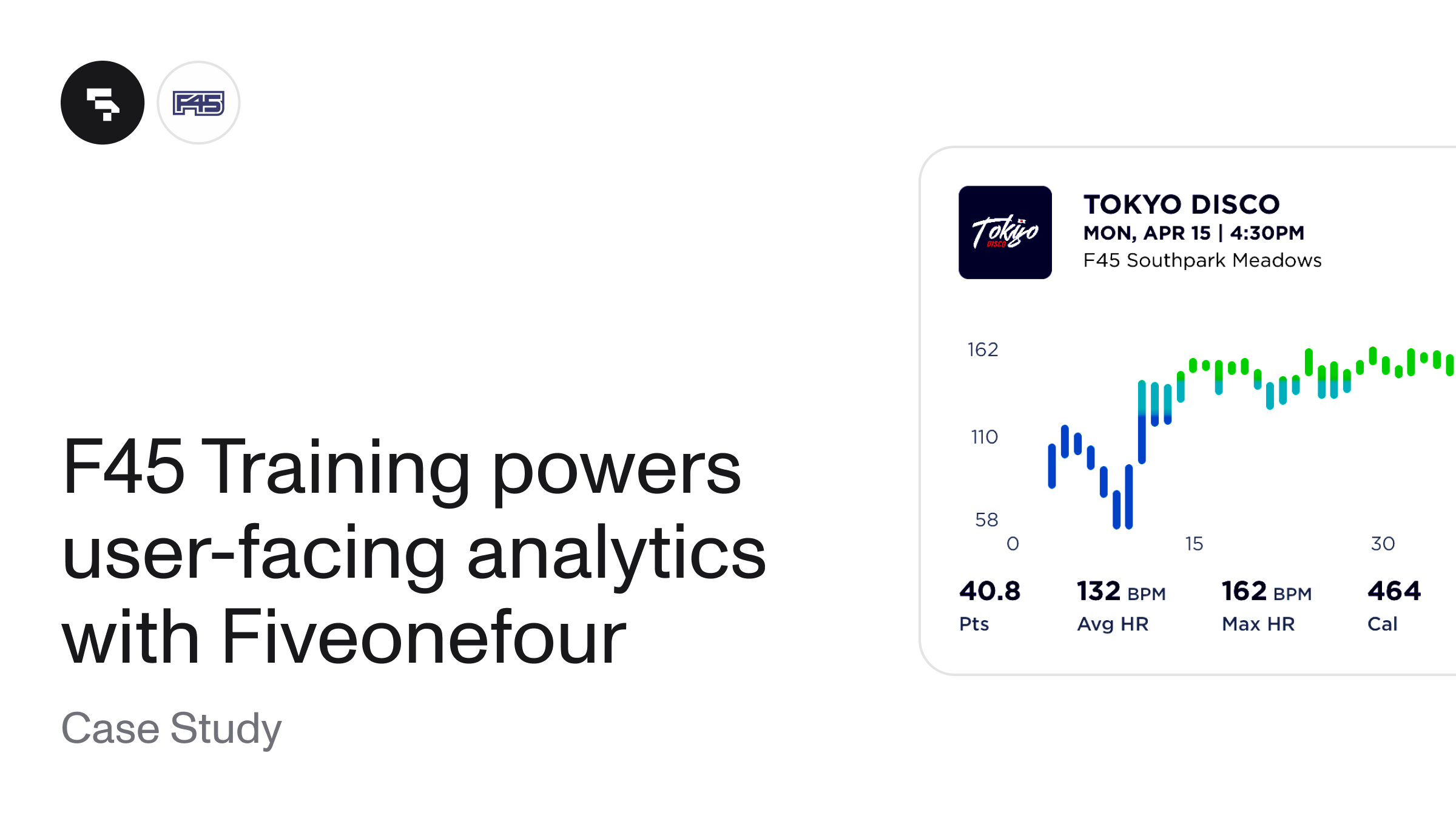
Case studies, User-facing analytics, Data Intensive Features
F45 Training Powers User-Facing Analytics with Fiveonefour
Discover how F45 Training, the global boutique fitness franchise, rolled out user-facing analytics 10x faster and 50% cheaper with Fiveonefour, unlocking an immersive mobile app experience for their Lionheart biometrics and connected-fitness users.

AI, Educational, Announcements, Product
Introducing Aurora Pre-Alpha Preview: API to ClickHouse demo
Download and try out Aurora's first workflow: getting data from an API into your clickhouse database!

Educational, Observability, Data Products
Data Mesh and Data Autonomy
A hands-on approach to domain-driven data products, automated data pipelines, and scalable governance.

Observability
Whoop There it is — Data Intensive Overhaul of Whoop

Data Products
We Built our Own Product Analytics with Moose (pt. 1)

Announcements
Welcome to the OG crew

Announcements, Product