Code first CDC from Postgres to ClickHouse with Debezium, Redpanda, and MooseStack
TL;DR
What: CDC from Postgres to Clickhouse as code
Why: Keep OLTP safe and fast while mirroring data near-real-time to OLAP for heavy reads and analytics.
How (at a glance): Postgres OLTP → Debezium CDC → Redpanda streaming ingest → ClickHouse OLAP (ReplacingMergeTree for upserts/deletes on merge).
Why MooseStack: Everything lives in code—from CDC streams through to OLAP tables. Moose dev server makes it trivial to spin up the full pipeline (ClickHouse, Redpanda, and your OLTP infrastructure too) locally in seconds.
Result: Safe OLTP, lightning-fast OLAP, and schema changes stay sane. Regenerate external models, adjust transform/table, keep streaming.
Replicating data from an OLTP (transactional) system to an OLAP (analytical) system should be simple. But there are fundamental differences between these two architectures that make it difficult. From optimizing writes to your OLAP system, to making sure you have the right ClickHouse table engine set up, there are many complexities to writing Change Data Capture (CDC) data to an OLAP database in a performant and easily queryable way.
So, why would you want to replicate your data to OLAP? To massively speed up your queries, and to be able to do so at scale without jeopardizing your transactional application.
There are two main ways to replicate data from OLTP to OLAP:
- Managed / configurable services: tools like ClickHouse ClickPipes are perfect if you’re using ClickHouse Cloud and want a low-ops way to move data. You configure sources and transformations through the UI, and ClickHouse takes care of ingestion and schema evolution automatically.
- Code-first pipelines: better suited for teams who want to own their data flow. You define ingestion, transforms, and OLAP tables in code, version them alongside your application, and deploy them like any other service. This approach gives you tighter control, testability, and local dev parity.
This article focuses on the as-code approach. It’s aimed at developers who’d rather define a pipeline once and have it run consistently in local dev, staging, and production.
That’s where MooseStack comes in: it’s the developer layer that sits on top of Redpanda and ClickHouse, giving you code-defined data infrastructure and a local development server that mirrors your full stack.
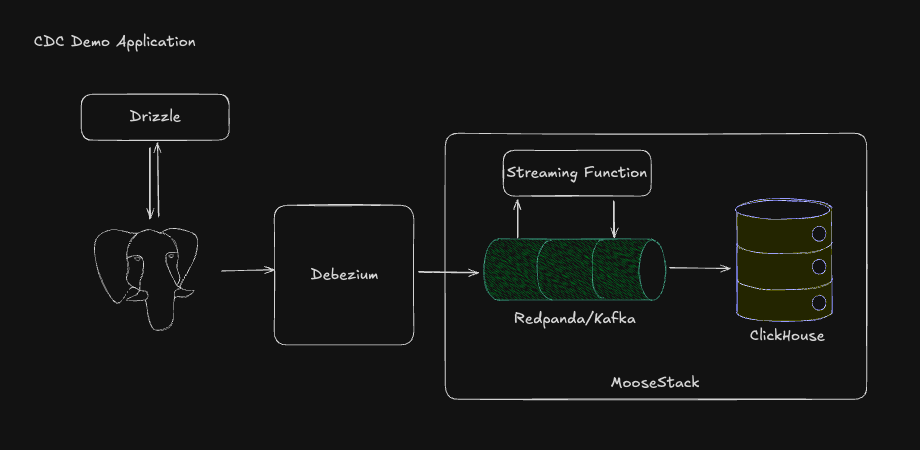
You model ingestion, transforms, and OLAP tables as code. That means: typed CDC events, typed tables, controlled migrations, and replay—all without hand‑rolling consumers.
In this demo application, the application runs a MooseStack instance that creates and connects:
- A local Postgres database and Drizzle to manage and write to your local Postgres
- Debezium, configured to extract data from Postgres’ write-ahead log
- MooseStack acts as the developer and management layer for your analytical pipeline: built on Redpanda and ClickHouse, but defined entirely in code. Its streaming layer receives Debezium’s CDC events, its transform functions map them into the OLAP-ready schema, and its OLAP module manages table definitions and writes into ClickHouse using best-practice engines like
ReplacingMergeTree.
This blog walks you through how to quickstart the app, and get everything running—so you can see how you can manipulate (create, update, delete) the data in the Postgres database live with Drizzle Studio, and see the changes in the data flow through in real time to ClickHouse. Then we’ll dive deep to help you understand what’s happening in each part of the application infrastructure, so you can apply the same architecture to your own app.
Quickstart
The application repo is here: https://github.com/514-labs/debezium-cdc
Prerequisites:
- Docker & Docker Compose (for running infrastructure)
- Node.js 20+ and pnpm (for Moose and Drizzle)
- Moose CLI:
bash -i <(curl -fsSL https://fiveonefour.com/install.sh) moose
Step 1: clone the repo and install
Make sure Docker Desktop is running.
Step 2: start the application
This may take a minute. It will run the application’s infrastructure. Open your Docker Desktop app, you can see what it set up!
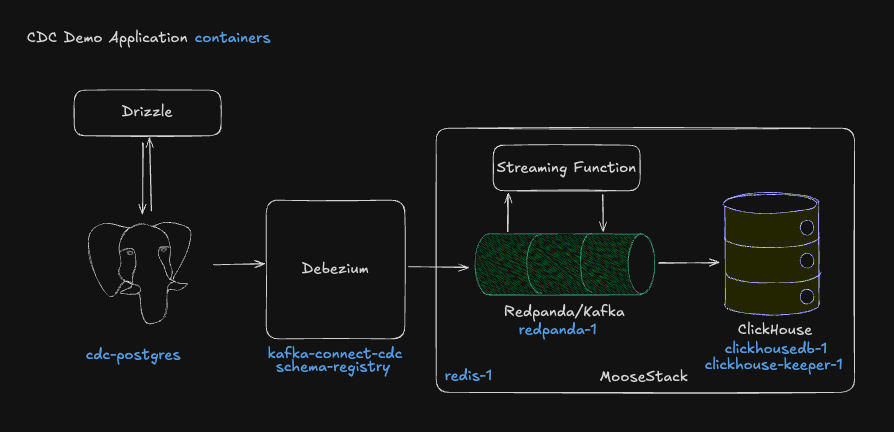
The diagram shows exactly what the app spins up (how containers map to the architecture). As soon as it starts, you’ll see the initial sync kick off (lots of logs) as data flows from Postgres into ClickHouse.
E.g.
You now have your Postgres and your ClickHouse databases set up and in sync.
Step 3: test CDC
If you want to see the CDC in action, in a new terminal, run Drizzle Studio:
Then open Drizzle Studio in your browser, at http://local.drizzle.studio/
Edit the data in the database: create a new row, delete a row, edit a row.
In your application terminal, you’ll be able to see the Moose Dev logs showing you the change data being streamed, transformed, and written to the database.
This will be written into your ClickHouse table, and because the table uses the ReplacingMergeTree table engine, on merge, those events will be deduplicated.
You can see the data in ClickHouse using your IDE’s database client. You can find the instructions for connecting to your local ClickHouse in the MooseOLAP docs. The deleted row CDCd from above is shown rationalized in ClickHouse in the screenshot be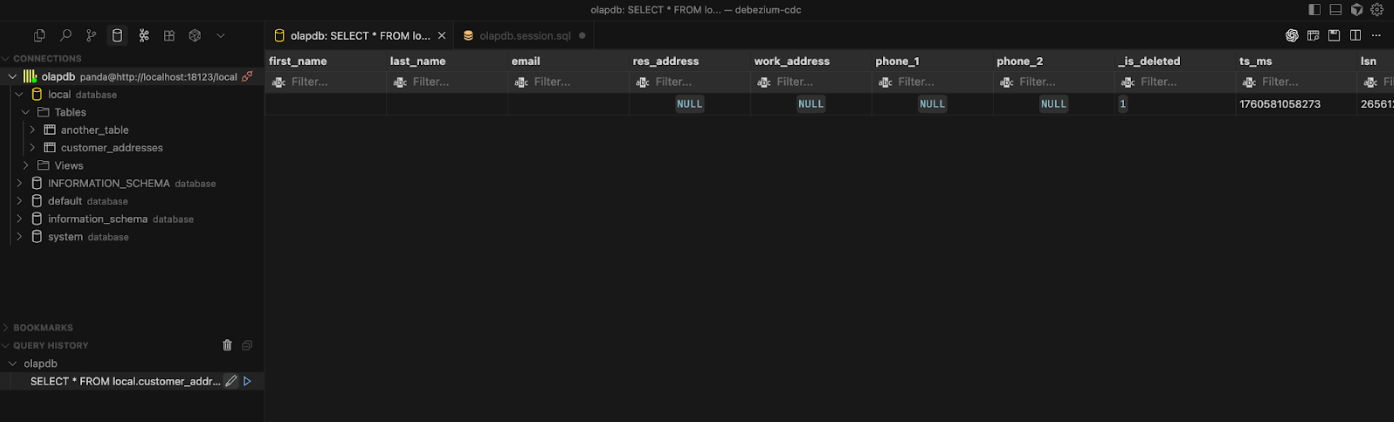
CDC to ClickHouse: as code (deep dive)
This section will walk you through how this application achieves the above.
- How the infrastructure is set up to run locally to give you a great developer experience (Moose Development Server and startup)
- How Postgres, Drizzle and Debezium are configured (Configuring Postgres with Drizzle, and wiring up Debezium and Redpanda with moose dev startup script hooks)
- How to pull Debezium’s managed Redpanda topics into code with the Moose CLI: allowing the creation of destination tables, streaming functions that conform the data to expectations, and syncs between kafka and ClickHouse (From CDC to OLAP with MooseStack)
Moose Development Server and startup
Running your MooseStack application in Development Mode (moose dev) allows you to spin up your OLAP infrastructure locally for development purposes. It reads your moose.config.toml and starts the required services, including ClickHouse and Redpanda.
Then it watches your application files, and hot-reloads your schema and function changes to your local ClickHouse and Redpanda. Super useful for when you are iterating on your schemas, streaming transformations, APIs, etc.
But sometimes, like in this demo, your development surface area extends outside of your OLAP infrastructure. That’s expected, and you probably still expect the same development experience.
So, moose dev allows you to extend the services that are spun up when you run the command. By way of example,this application adds Postgres, Kafka Connect with Debezium and Apicurio’s schema registry.
From docker-compose.dev.override.yaml
Now, running moose dev spins up the MooseStack services (ClickHouse and Redpanda) and the above: you’ve got your end to end dev stack for building and testing your CDC implementation managed with a single command
Configuring Postgres with Drizzle, and wiring up Debezium and Redpanda with moose dev startup script hooks
moose dev also gives us hooks to be able to run scripts at startup (see /moose.config.toml, where the application references on_first_start_script = "./setup-cdc.sh"). Let’s go through the interesting parts:
From setup-cdc.sh:
This is doing three main things:
- With
db:push(which runs the Drizzle CLI’sdrizzle-kit pushcommand), Drizzle uses the data models inapp/oltp/schema.tsto create tables in Postgres. - With
db:seed 10(which runsapp/oltp/seed.ts) 10 rows of data are written into Postgres (change this if you want more data). - With the
curlcommand at the end, the application configures a Kafka Connect connection with reference topostgres-connector.json: allowing the CDC data that is pushed from Postgres with Debezium to be published to Redpanda.
With this, Debezium creates Redpanda topics for each table fitting the configuration (here "table.include.list": "public.*",).
So, to be clear, at this moment, the application has (see blue, below):
- Set up all the infrastructure
- Created tables in Postgres
- Seeded Postgres with 1k rows of data
- Configured Debezium to create a topic in Redpanda for each table in Postgres, and push the changes
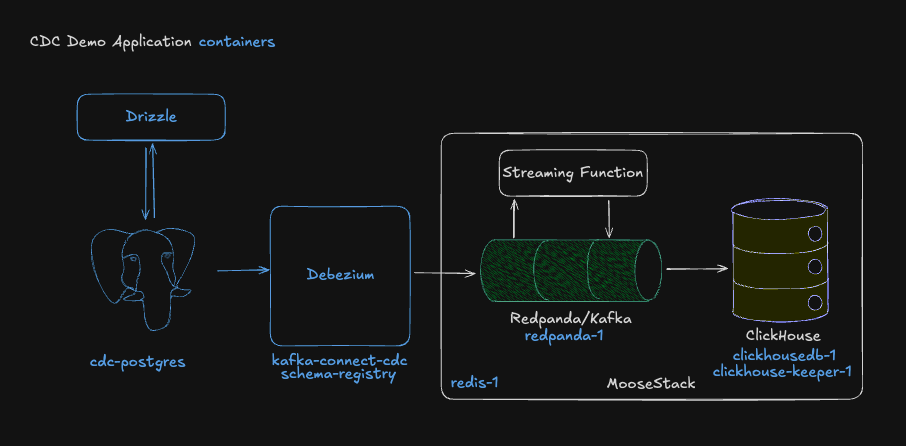
Now that the OLTP database and CDC provider are emitting events, it’s time to transform those events for the ReplacingMergeTree engine and make sure they’re being written efficiently.
From CDC to OLAP with MooseStack
To be able to land the data in ClickHouse, the remaining steps are:
- Discover CDC topics and generate external stream models
- Make the streams type‑safe (Drizzle → MooseStack)
- Define MooseOLAP object, and ClickHouse table (with ReplacingMergeTree)
- Transform Debezium event → OLAP row
- Sync data from stream to ClickHouse table
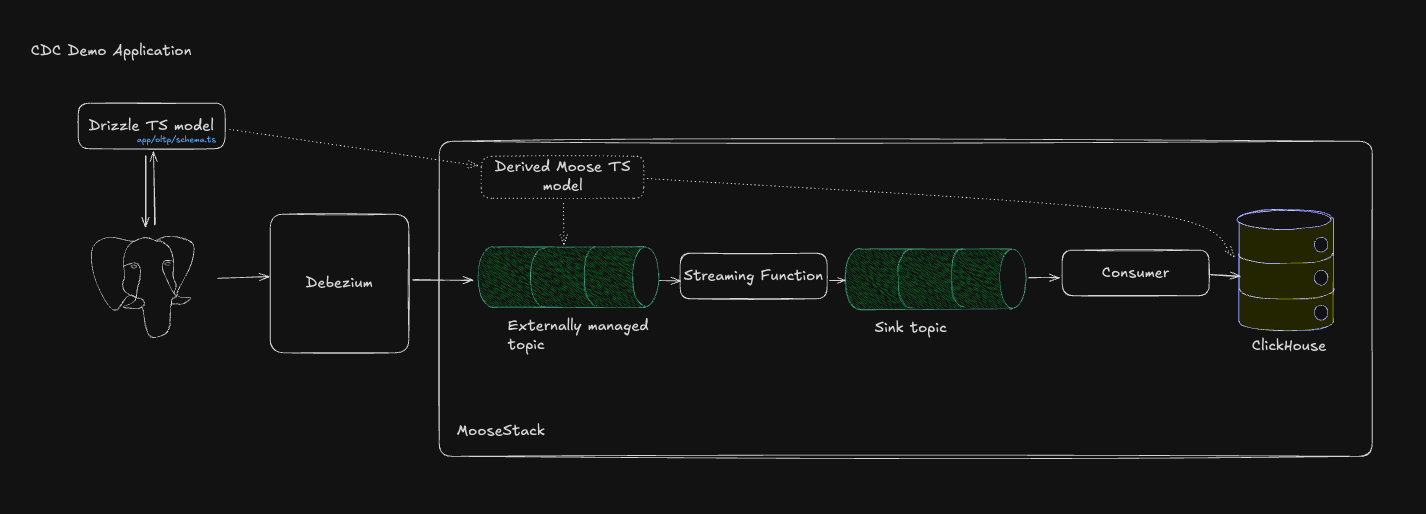
1. Discover CDC topics and generate external stream models
In creating this application, we used the moose kafka pull command to generate TypeScript Stream objects from the Debezium managed Redpanda topics. You can optionally supply a URL to your schema registry to generate types for each topic (JSON supported, Avro coming soon).
This writes (and overwrites) generated files under app/cdc/1-sources/. These streams are externally managed—MooseStream doesn’t create the topics; it connects to them.
From app/cdc/1-sources/externalTopics.ts:
Define a stable, versioned representation of your upstream streaming data sources in code. This code-first foundation lets you build the rest of your data pipeline (routing, transforming, and syncing into OLAP storage). When the schema changes, just regenerate and your app stays in lockstep.
2. Make the streams type‑safe (Drizzle → Moose)
Generated streams are untyped by default; the application derives types to preserve type safety during transformations.
Re‑use your Drizzle model so transforms are fully typed.
From app/cdc/1-sources/typed-topics.ts:
Carrying Drizzle models into the CDC pipeline keeps OLTP and OLAP code in sync. No duplicate model drift.
3. Define Moose OLAP object, and ClickHousetable (with ReplacingMergeTree)
Adapt the base OLTP models to OLAP by adding CDC‑specific columns (used by ReplacingMergeTree) and ClickHouse-optimized typing. (Low‑cardinality strings are a nice win on country/state.)
(If you want a deep dive into why this application uses ReplacingMergeTree, see yesterday’s blog on Table Engines and CDC).
From app/models.ts:
Then configure the OlapTable for proper use with the ReplacingMergeTree table engine.
From app/cdc/3-destinations/olap-tables.ts:
ClickHouse stays append‑only (fast), and merges reconcile state (updates/deletes) using your version (ver) and delete (isDeleted) fields.
4. Transform Debezium event → OLAP row
Unwrap once, keep it boring (that’s the goal). You can also denormalize here if you like.
From app/cdc/2-transforms/payload-handler.ts:
Use the above to create the transform function.
From app/cdc/2-transforms/customer-addresses.ts:
5. Sync data from stream to ClickHouse table
Wire the transform to a sink stream that writes to the table.
From app/cdc/3-destinations/sink-topics.ts:
This gets you from raw Debezium output:
To a processed row (ready for ClickHouse’s ReplacingMergeTree tables):
Conclusion
You now have safe OLTP and near-real-time OLAP. Debezium emits WAL changes, Redpanda buffers them, and ClickHouse lands the latest state with append-only speed. MooseStack helps you glue it all together without hand-rolling connectors, keeps schemas and transforms in code, and runs everything locally so you can iterate quickly.
The real advantage shows up over time: because ingestion, transforms, and OLAP models all live in code, schema changes and data quality issues are governed with git, not guessed at. Moose generates migrations, isolates misaligned events in DLQs, and keeps your data contracts versioned and reviewable: the same way you manage your application code.
In the next releases, we’ll build on this foundation: modeling analytical views and derivative tables for fast metrics, time-series, and drill-downs. All still defined as code and typed end to end.
Interested in learning more?
Sign up for our newsletter — we only send one when we have something actually worth saying.
Related posts
All Blog Posts
OLAP
OLAP migration complexity is the cost of fast reads
In transactional systems, migrations are logical and predictable. In analytical systems, every schema change is a physical event—rewrites, recomputations, and dependency cascades. This post explains why OLAP migrations are inherently complex, the architectural trade-offs behind them, and how to manage that complexity.

OLAP, Product
Ship your data with Moose APIs
You’ve modeled your OLAP data and set up CDC—now it’s time to ship it. Moose makes it effortless to expose your ClickHouse models through typed, validated APIs. Whether you use Moose’s built-in Api class or integrate with Express or FastAPI, you’ll get OpenAPI specs, auth, and runtime validation out of the box.